What is Dynamic Programming
- Dynamic Programming is a method for solving complex problems by breaking them down into simpler subproblems. It involves solving each subproblem just once and storing the solution (memoization) to avoid redundant computations.
- The simplest way to tackle dynamic programming problems is through recursion with memoization. However, the most efficient approach is often using the bottom-up method, known as tabulation
- Video explanations:
Tips for Dynamic Programming
- In recursive problem-solving, it's crucial to
- Visualize the Problem:
- Utilize common visualization approaches such as decision trees or acyclic graphs.
- Define the starting point (root node) and outline paths to reach base cases (leaf nodes).
- Utilize common visualization approaches such as decision trees or acyclic graphs.
- Identify Repetitive Calculations:
- Recognize computations that recur across different subproblems.
- Apply memoization to store and reuse solutions to these subproblems, aligning with dynamic programming principles.
- Visualize the Problem:


DP Implementation Types
There are two ways to implement a DP algorithm:
- Top-down, also known as memorization.
- Top-down is implemented with recursion and made efficient with memorization.
- A top-down implementation is usually much easier to write. This is because with recursion, the ordering of sub-problems does not matter, whereas with tabulation, we need to go through a logical ordering of solving sub-problems.
#Top-down, also known as memorization.
memo = {}
def fibo(n):
if n in [0,1]:
return n
if n not in memo:
memo[n] = fibo(n-1) + fibo(n-2)
return memo[n]
print(fibo(5))
- Bottom-up, also known as tabulation.
- Bottom-up is implemented with iteration and starts at the base cases.
- A bottom-up implementation runtime is usually faster, as iteration does not have the overhead that recursion does.
# Bottom-up, also known as tabulation.
def fibo(n):
arr = [0] * (n+1)
arr[0] = 0
arr[1] = 1
for i in range(2, n+1):
arr[i] = arr[i-1] + arr[i-2]
print(arr)
return arr[n]
print(fibo(5))
DP Vs Greedy Algo
- If a problem is asking for the maximum/minimum/longest/shortest of something, the number of ways to do something, or if it is possible to reach a certain point, it is probably greedy or DP.
- Thus, how do we know which algo to use
- The characteristic that is common in DP problems is that future "decisions" depend on earlier decisions.
- Deciding to do something at one step may affect the ability to do something in a later step.
- This characteristic is what makes a greedy algorithm invalid for a DP problem - we need to factor in results from previous decisions.
- With greedy at each step we decide the best value not caring about past decisions
Common DP Patterns
1 Dimension Problem
- Given just an array:
- Visualize the problem as a directed acyclic graph (DAG) where each element points to subsequent elements based on the problem's constraints (e.g., increasing subsequence).
- Steps:
- Define the state: Identify the parameters that define the state (often just one index).
- Recurrence relation: Determine how the current state depends on previous states.
- Order of computation: Decide if you need to process the array from left to right, right to left, or in sorted order.
- Base cases: Set up the initial conditions.
- Fill the DP array: Use the recurrence relation to fill the array.
- Extract the solution: The answer is usually at the last iterated index or can be derived from it.
Longest Increasing Sub-sequence
-
Description: Given an array of integers, find the length of the longest subsequence where elements are in strictly increasing order.
-
Aka: Fibonacci sequence problems
-
Example problems:
- Longest Increasing Sub-sequence
- Climbing Stairs
- House robber
-
def longest_increasing_subsequence(arr):
n = len(arr)
if n == 0:
return 0
# Initialize the dp array where dp[i] represents the length of the LIS ending at index i
dp = [1] * n
# Fill the dp array
for i in range(1, n):
for j in range(i):
if arr[i] > arr[j]:
dp[i] = max(dp[i], dp[j] + 1)
# The length of the longest increasing subsequence
return max(dp)
# Example usage
arr = [10, 22, 9, 33, 21, 50, 41, 60, 80]
lis_length = longest_increasing_subsequence(arr)
print(f"The length of the longest increasing subsequence is: {lis_length}")
- Longest Increasing Subsequence has interesting solutions based on DFS and binary search.
2 Dimension Problems
- Given two variables:
- Visualize the problem as a matrix or a decision tree where each cell or node represents a state defined by two parameters.
- Steps:
- Define the state: Identify the two parameters that define the state.
- Recurrence relation: Determine how the current state depends on previous states.
- Order of computation: Decide the order to fill the matrix (often row-wise or column-wise).
- Base cases: Set up the initial conditions.
- Fill the DP matrix: Use the recurrence relation to fill the matrix.
- Extract the solution: The answer is usually at the last iterated cell of the matrix or can be derived from it.
1/0 Knapsack
- The 0/1 Knapsack problem is a classic optimization problem where you have a set of items, each with a weight and a value, and a knapsack with a maximum weight capacity.
- The goal is to determine the maximum value of items that can be included in the knapsack without exceeding its weight capacity.
- Example Problems:
- Target Sum
- Partition Equal Subset Sum
Memoization
def dfs(index, nums):
# base case
if index == len(nums):
return 0
#skip item i: decision one(d 1)
exclude = dfs(index + 1, nums)
# include item i: d 2
if certain condition met:
include = nums[i] + dfs(i+1, nums)
return max(include, exclude)
#with memo
def dfs(index, nums):
# base case
if index == len(nums):
return 0
if index in memo:
return memo[index]
#skip item i: decision one
exclude = dfs(index + 1, nums)
# include item i: d 2
if certain condition met:
include = nums[i] + dfs(i+1, nums)
memo[index] = max(include, exclude)
return memo[index]
#call function
dfs(0, [...])
Tabulation
def knapsack(values, weights, capacity):
n = len(values)
# Initialize a 2D DP array, where dp[i][w] represents the maximum value
# that can be obtained with the first i items and a knapsack capacity of w.
dp = [[0] * (capacity + 1) for _ in range(n + 1)]
# Fill the DP table
for i in range(1, n + 1):
for w in range(1, capacity + 1):
if weights[i - 1] <= w:
# Include the current item and check if it yields a better value
dp[i][w] = max(dp[i - 1][w], dp[i - 1][w - weights[i - 1]] + values[i - 1])
else:
# Exclude the current item
dp[i][w] = dp[i - 1][w]
# The maximum value that can be obtained with the given capacity
return dp[n][capacity]
# Example usage
values = [60, 100, 120]
weights = [10, 20, 30]
capacity = 50
max_value = knapsack(values, weights, capacity)
print(f"The maximum value that can be obtained is: {max_value}")
Unbound Knapsack
- The Unbounded Knapsack problem is similar to the 0/1 Knapsack problem, but with one key difference: each item can be used an unlimited number of times.
- Implementation-wise, the unbounded knapsack problem is similar to the 0/1 knapsack problem. However, in the unbounded knapsack problem, you can use values from the current row, whereas in the 0/1 knapsack problem, you need to refer to values from previous rows.
- Example problems:
- Minimum cost for Tickets
- Rod Cutting
- Coin Change 1 and 2
- Maximize the Stock Profit
Memoization
def dfs(index, nums):
# base case
if index == len(nums):
return 0
#skip item i: decision one
exclude = dfs(index + 1, nums)
# include item i: and recurse on it again
if certain condition met:
include = nums[i] + dfs(i, nums) #notice we're still using i
return max(exclude, include)
Optimization with Multiple Branch
- While above recursions can be a powerful and elegant for solving certain problems, loops are generally more efficient in terms of time and space complexity.
- For problems like the Unbounded Knapsack, where each item can be used multiple times, an iterative approach with a loop is often more suitable and performant.
def dfs(index, nums):
if index == len(nums):
return 0
res = float("-inf")
for i in range(index, len(nums)):
if certain_condition:
res = max(res, dfs(i+1, nums))
return res
# with memo
def dfs(index, nums):
if index == len(nums):
return 0
if index in memo:
return memo[index]
res = float("inf")
for i in range(index, len(nums)):
if certain_condition:
res = max(res, dfs(i+1, nums))
memo[index] = res
return memo[index]
Tabulation
def unbounded_knapsack(capacity, weights, values):
n = len(weights)
# Create a table to store results of subproblems
dp = [[0] * (capacity + 1) for _ in range(n + 1)]
# Build dp array in bottom-up manner
for i in range(1, n + 1):
for w in range(1, capacity + 1):
if weights[i - 1] <= w:
# If the current item can be included, decide whether to include it or not
dp[i][w] = max(dp[i - 1][w], values[i - 1] + dp[i][w - weights[i - 1]])
else:
# If the current item cannot be included, take the value without including it
dp[i][w] = dp[i - 1][w]
# Return the maximum value that can be obtained with the given capacity
return dp[n][capacity]
# Example usage
values = [10, 40, 50, 70]
weights = [1, 3, 4, 5]
capacity = 8
max_value = unbounded_knapsack(values, weights, capacity)
print(f"The maximum value that can be obtained is: {max_value}")
Longest Common Subsequence
- LCS (Longest Common Subsequence) refers to the longest sequence that can be found in both of given strings.
- This subsequence is different from a substring because the characters in an LCS do not need to appear consecutively, but their order must be preserved.
- See also Longest Substring Without Repeating Characters a related problem.
- They are widely applicable in various fields, especially where sequence comparison and alignment are crucial.
- Example problems:
- Longest Common Subsequence
- Edit Distance
- Distinct Subsequence
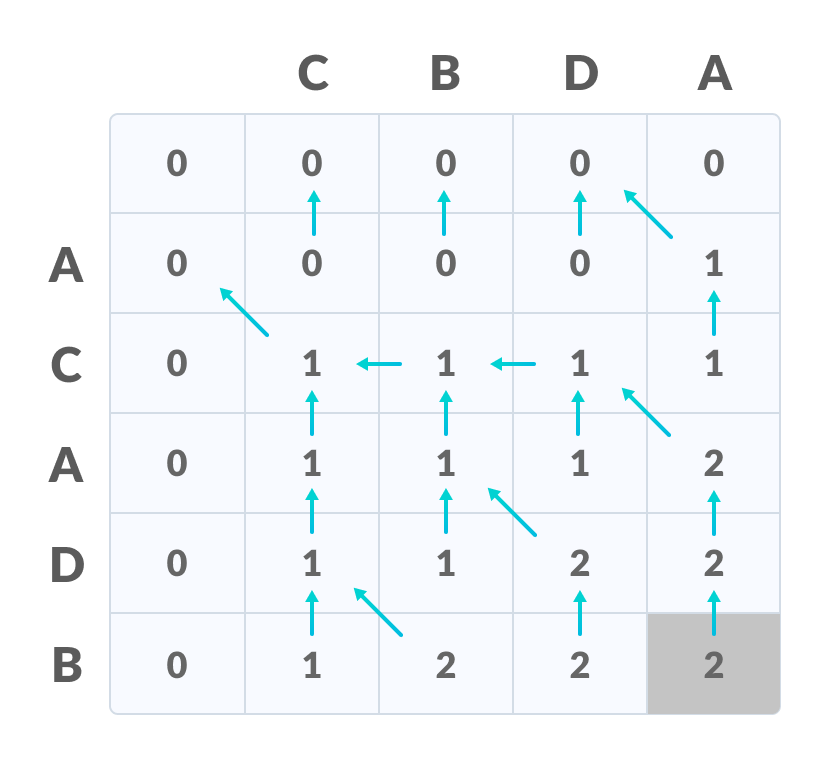
def longest_common_subsequence(X, Y):
m = len(X)
n = len(Y)
# Initialize the DP table with zeros
dp = [[0] * (n + 1) for _ in range(m + 1)]
# Fill the DP table
for i in range(1, m + 1):
for j in range(1, n + 1):
if X[i - 1] == Y[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
# The length of the longest common subsequence
return dp[m][n]
# Example usage
X = "CBDA"
Y = "ACADB"
lcs_length = longest_common_subsequence(X, Y)
print(f"The length of the longest common subsequence is: {lcs_length}")
Longest Palindromic Substring
-
Description: Given a string, find the longest substring that is a palindrome (reads the same forwards and backwards).
-
Example problems:
- Longest palindromic substring
- Palindromic substrings
- Longest palindromic subsequence
-
Using two expanding windows approach
class Solution:
def longestPalindrome(self, s: str) -> str:
self.resString = ""
self.maxLength = 0
self.s = s
def runCheckPalindrom(left, right):
while left >=0 and right < len(self.s) and s[left] == s[right]:
if (right-left + 1) > self.maxLength:
self.resString = s[left:right+1]
self.maxLength = right-left+1
left -= 1
right += 1
for i in range(len(s)):
runCheckPalindrom(i,i) #for odd
runCheckPalindrom(i,i+1) #for even
return self.resString
- Tabulation approach
def longest_palindromic_substring(s):
n = len(s)
if n == 0:
return ""
# Initialize the dp table
dp = [[False] * n for _ in range(n)]
start = 0
max_length = 1
# All substrings of length 1 are palindromes
for i in range(n):
dp[i][i] = True
# Check for substrings of length 2
for i in range(n - 1):
if s[i] == s[i + 1]:
dp[i][i + 1] = True
start = i
max_length = 2
# Check for lengths greater than 2
for length in range(3, n + 1):
for i in range(n - length + 1):
j = i + length - 1
if s[i] == s[j] and dp[i + 1][j - 1]:
dp[i][j] = True
start = i
max_length = length
# Return the longest palindromic substring
return s[start:start + max_length]
# Example usage
s = "babad"
longest_palindrome = longest_palindromic_substring(s)
print(f"The longest palindromic substring is: {longest_palindrome}")
Additional Tips
- Practice: Regular practice is key to mastering DP. Solve a variety of problems to get a feel for different types of states and recurrence relations.
- Optimizations: Be aware of space optimizations (e.g., using 1D array for 2D problems when only the previous row is needed).
- Edge Cases: Always consider edge cases and handle them appropriately in your base cases and recurrence relations.