Introduction
What Is RAG?
- Retrieval-Augmented Generation (RAG)
- A technique that enhances AI large language models (LLMs) by incorporating additional contextual information not present in their default training data, such as:
- Internal company documents (e.g., private knowledge bases not publicly available)
- Up-to-date or real-time search results
- Answers to customer questions based on historical FAQs
How Does it Work (high-level)?
- When a user asks a question, relevant information is retrieved from a database or archive and provided to the AI as context. This equips the model with new, pertinent details to generate a response.
Questions?
- Why use an LLM instead of just returning the archive data directly?
- The retrieved data is often unstructured yet relevant. The LLM processes this into a coherent, user-friendly format that’s easier to understand.
- Won’t the LLM mix in extra information from its own knowledge base?
- Yes, it might attempt to supplement the answer with its pre-existing knowledge. To prevent this, you can give the LLM strict instructions, such as:
- "Only use the provided context to answer the question. If no answer can be inferred, respond with 'I cannot find any relevant information.'" But this is weak as it depends on the model's instructions following capabilities.
- Yes, it might attempt to supplement the answer with its pre-existing knowledge. To prevent this, you can give the LLM strict instructions, such as:
- If a model has large context window why not through everything(documents, instructions…) on to the prompt?
- In reality longer contexts do not generate better responses, overloading your context can cause agents and applications to fail. in such a way such as contexts can become poisoned, distracting, confusing or conflicting.
- How Long Contexts Fail | Drew Breunig
Detailed: How Does RAG Work?
- There are various ways to implement RAG (which we’ll explore later), but the fundamental and most commonly used approach is outlined below. We’ll discuss why vector representations are used in a later section.
Data Conversion Stage:
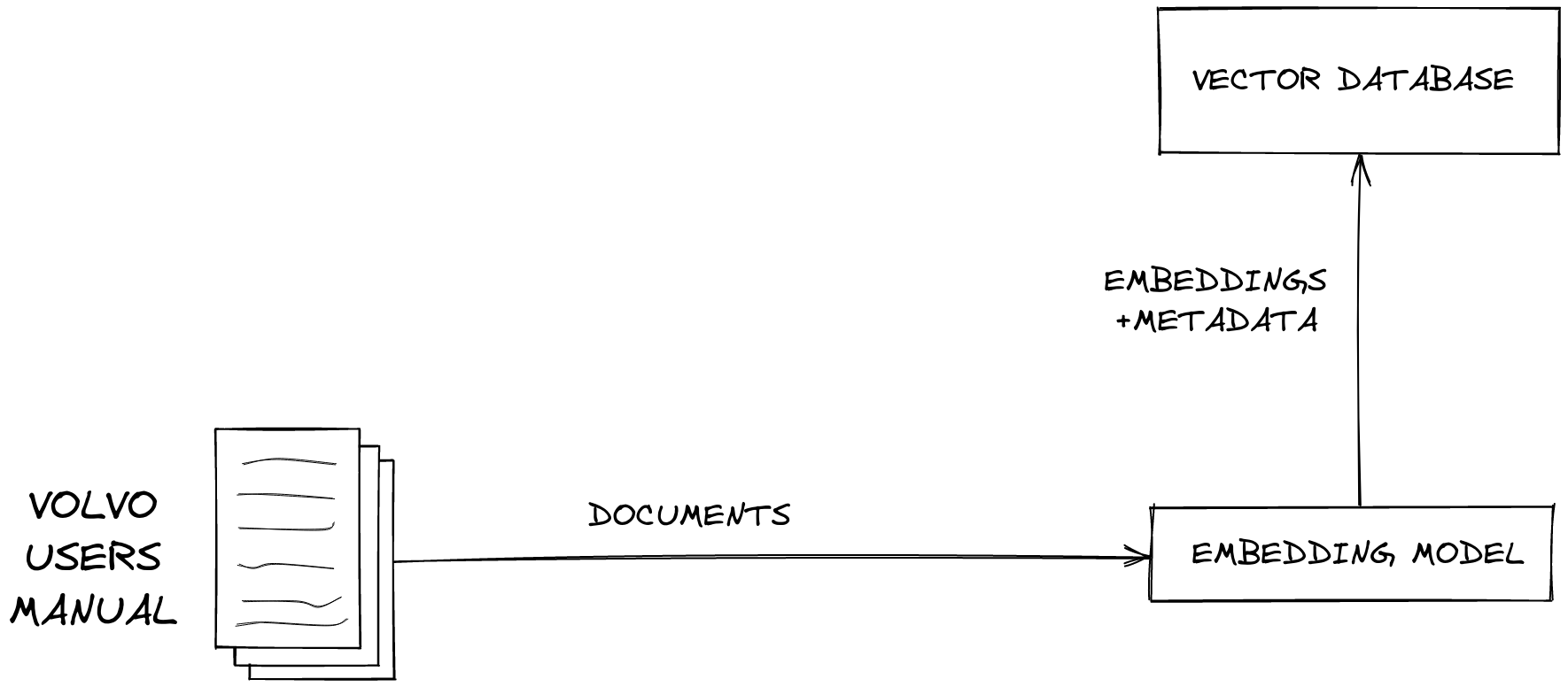
- Step 1: Chunking the Data
- First, you break your data into smaller pieces, or "chunks."
- Why chunk the data?
- Converting an entire document into a single vector isn’t practical—it loses too much relevant detail.
- Smaller chunks (e.g., a PDF page, a paragraph, or sections of ~1,000 characters) allow specific, meaningful content to be retrieved and used in building answers.
- Embedding models often have limits, and a whole document may exceed what they can process effectively.
- Step 2: Vector Representation
- Each chunk is converted into a vector representation using an embedding model.
- These vectors are numerical encoding that capture the semantic meaning of the text.
- Step 3: Storage
- The resulting vectors are stored in a vector database.
- This database allows for real-time searching, updating, or retrieval as needed.
Context Fetching Stage:
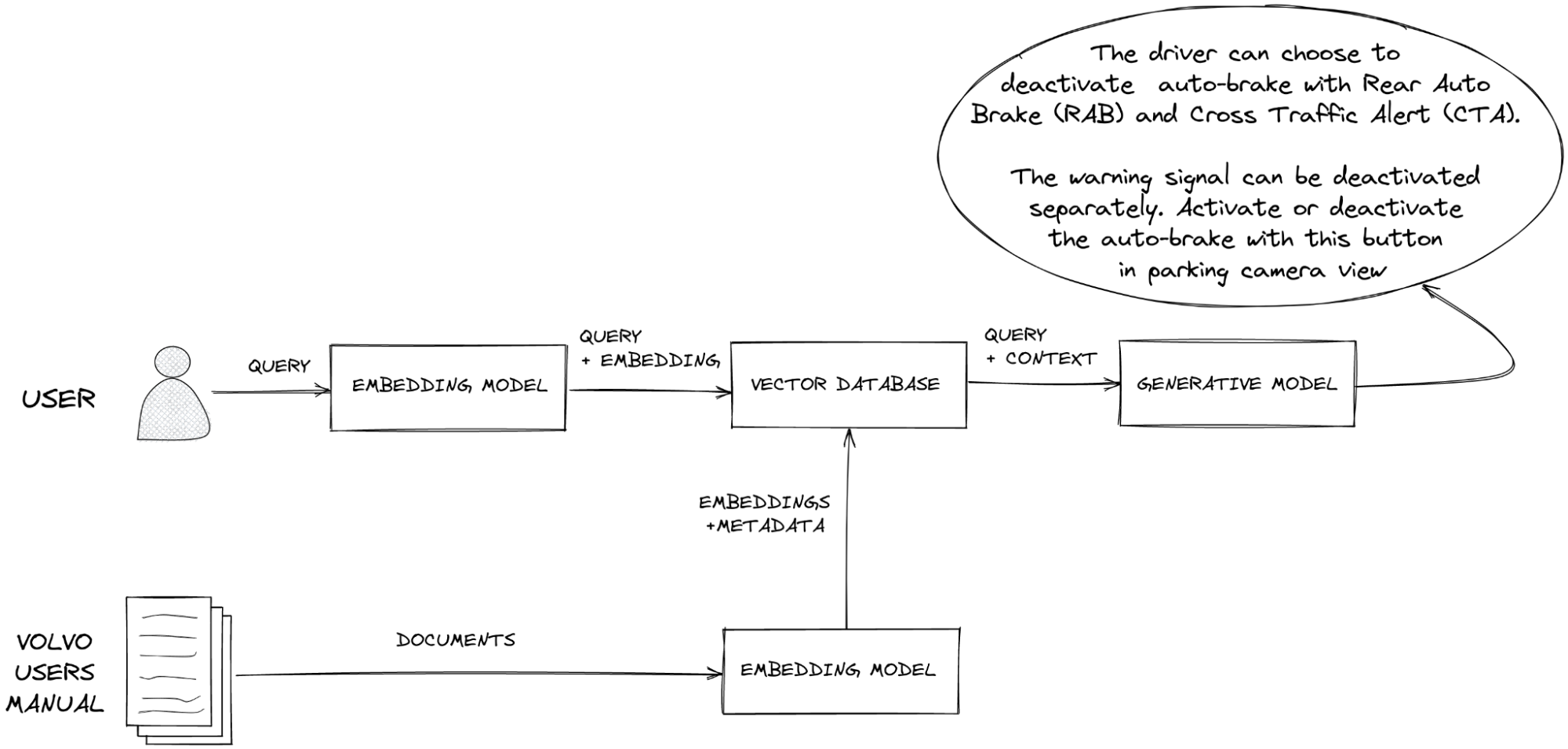
- Step 1: User Query
- A user submits a query seeking information.
- Step 2: Query Embedding
- The query is passed through the same embedding model to generate its vector representation.
- Step 3: Vector Search
- The system performs a k-nearest neighbor (k-NN) search in the vector database, typically using cosine similarity, to identify vectors (and their corresponding chunks) that are contextually similar to the query.
- Key Details:
- This is often called "dense search" or "dense retrieval."
- It functions as a semantic search, meaning it interprets the intent and meaning behind the query rather than relying solely on keyword matches.
- Semantic search considers context, relationships, and concepts in both the query and stored content.
- Example: A search for "Jaguar car" retrieves results about the car brand, not the animal.
- Step 4: Context Delivery
- The relevant chunks retrieved from the vector database (the "context") are combined with the user’s query and sent to the LLM via its context window.
- Step 5: Response Generation
- With access to recent and relevant data it didn’t previously have, the LLM can generate a more accurate response with reduced hallucination.